

Tiempo de lectura: 4 minutos.
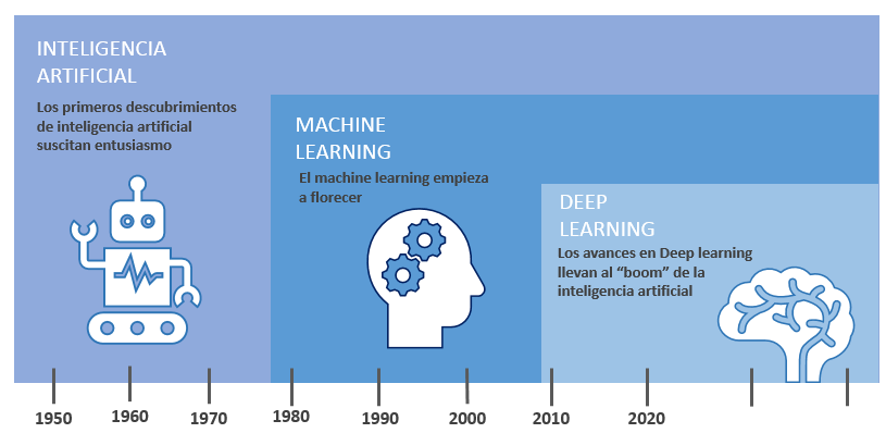
El Aprendizaje Automático, del inglés machine learning, es una rama de la Inteligencia Artificial. Su principal objetivo es desarrollar técnicas que permitan a las computadoras aprender. Se centra en el desarrollo de programas informáticos con la capacidad de cambiar cuando se exponen a nuevos datos. En otras palabras, detectar patrones en los datos estudiados y que las acciones del programa se ajusten en consecuencia.
Algoritmos
Dentro del Machine Learning, los algoritmos existentes se dividen en dos grandes grupos. Por una parte están los Supervisados, del inglés Supervised Learning, que se dividen en algoritmos de clasificación y de regresión. Por otra parte tenemos los No Supervisados, del inglés Unsupervised Learning, donde encontramos algoritmos de clustering y de reducción de la dimensionalidad. Dependiendo de los datos que poseamos, terminaremos usando un algoritmo u otro dentro de esos dos grandes grupos.
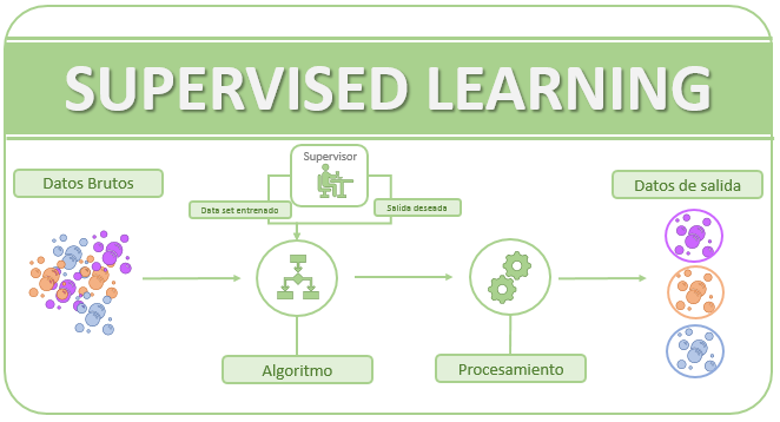
En el Supervised Learning, los datos de entrada son inicialmente de entrenamiento y están etiquetados. Estos datos son proporcionados al algoritmo, el cual, los procesa y extrae un modelo. Este modelo podrá etiquetar los nuevos datos que lleguen al sistema. Un ejemplo sería el correo spam. Cada vez que clasificamos un correo recibido como spam, el algoritmo mejora su precisión para catalogarlo automáticamente como tal. Así, el algoritmo llega a tener la suficiente confianza para clasificar los correos sin necesidad de consultar al usuario.
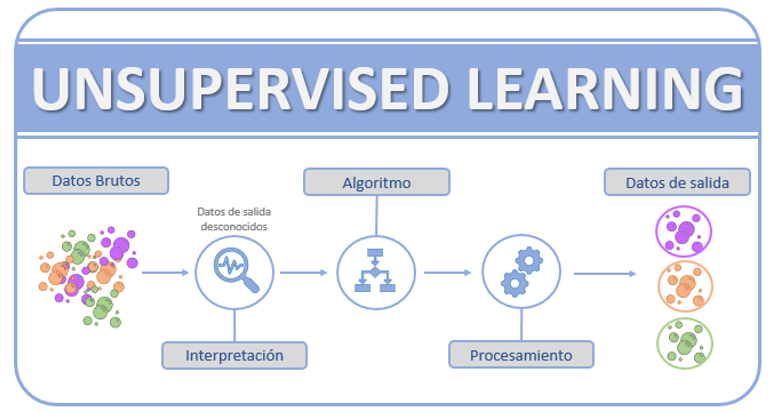
En el Unsupervised Learning, los datos de entrada no tienen ninguna etiqueta, es el propio algoritmo el que debe extraer patrones para crear un modelo. De esta forma, es capaz de detectar anomalías o semejanzas que los datos posean. Un ejemplo serían las técnicas de marketing usadas en los supermercados para la colocación de los productos. Se estudian un número de cestas de la compra, como datos de entrada, y se construyen modelos de tendencias con un cierto nivel de confidencia.
Mitos
Como ocurre con muchas nuevas tecnologías, el Machine Learning ha causado un efecto ‘fiebre del oro’ en muchas industrias. Hoy en día, se habla de tal cantidad de productos que “incorporan” el aprendizaje automático que el concepto está comenzando a perder su actual significado. Los mitos e ideas erróneos sobre el tema pueden volverse muy densos. Por ello, a continuación expondremos los más importantes para tener una idea más clara sobre el panorama actual.
“Inteligencia Artificial y Machine Learning son lo mismo
La diferencia entre estos dos conceptos es probablemente el punto más importante. Sin tener conocimientos en este campo, es normal que nunca te hayas planteado si realmente el Machine Learning y la Inteligencia Artificial hacen referencia a lo mismo. La Inteligencia Artificial es un campo de la informática. Está destinada al desarrollo de ordenadores capaces de hacer tareas normalmente realizadas por personas, más en concreto, tareas asociadas a personas actuando de forma inteligente. En cambio, el Machine Learning es un tipo de Inteligencia Artificial que le permite a un dispositivo acceder a datos de los que más tarde aprenderá.
“El modelo aprende por sí solo, así que no hay mucho que hacer”
Está muy generalizada la idea de que el Machine Learning mejora automáticamente con el tiempo, como si tuviera algún tipo de súperpoder. La realidad es que todavía está muy lejos de ser autónomo. El modelo encontrará relaciones, pero necesita direcciones y datos. En cuanto a su funcionamiento, el primer paso es entrenar el sistema con datos históricos. Más tarde utiliza lo aprendido para clasificar nuevas observaciones recibidas que nunca haya visto. Estas clasificaciones deben ser revisadas por un técnico, ya que pueden ser incorrectas y habría que modificar o re-entrenar el algoritmo.
Dentro de este mito es interesante mencionar la existencia del Aprendizaje por Refuerzo, del inglés Reinforcement Learning. Es actualmente la herramienta más cercana a ser autónoma. Lo que hace es; determina qué acciones debe escoger un agente de software en un entorno concreto con el fin de maximizar la recompensa.
“Funciona en cualquier situación”
¡No hay que confundirse! El Machine Learning no es una panacea, no se dispone de un ‘plugin de Machine Learning’ capaz de darle capacidad cognitiva a tecnologías ya existentes. El Machine Learning es usado solo si se poseen grandes conjuntos de datos. Primero se define el problema y se identifica una tecnología para resolverlo. Luego se entrena la herramienta con los datos adecuados y se verifica la validez de los resultados. Incluso los algoritmos más potentes del Machine Learning tienen que ser cuidadosamente revisados periódicamente para que no se salgan de su cometido. No tiene sentido gastar miles de euros en crear una solución personalizada cuando, en la mayoria de los casos, una persona puede realizar ese análisis de forma sencilla.
“Nunca falla”
Cada problema requiere una solución diferente, por lo que utilizar el algoritmo erróneo lleva al fracaso de toda la solución. Para elegir el algoritmo correcto, se necesita tener claro los datos que tienes y que es realmente lo que deseas que el algoritmo haga por ti.
Por otra parte, que el algoritmo muestre una precisión muy alta (p. ej. 99%), es una señal de que probablemente el modelo está sobreentrenado. ¿Esto que quiere decir? Que la predicción que hemos realizado se ajusta demasiado (over-fitting) a los datos con los que el modelo ha sido entrenado. Esto provocará un elevado margen de error cuando examinemos nuevas observaciones.
Conclusión
El Machine Learning ha abierto una nueva puerta a la imaginación, haciendo realidad muchas cosas impensables hace una década. Queda claro que es una herramienta muy potente, pero siempre y cuando se sepa cómo utilizar. El estudio previo de los datos que entrenaremos es fundamental, ya que en muchos casos a primera vista se puede descartar la viabilidad del proyecto. También es importante tener claro que los algoritmos de Machine Learning no harán milagros y que tampoco obtendremos siempre los resultados deseados.
Autora: Sara Estévez Manteiga, Área Big Data





