
Que vivimos en la era de la transformación digital es un hecho. Todos habréis oído hablar de ella y aplica en mayor o menor medida a diferentes ámbitos de nuestra vida: ámbito laboral, personal, compras, comunicaciones, entretenimiento… Una de las características principales de esta transformación es la generación de grandes cantidades de datos, que procesados y analizados de la manera correcta pueden aportar valor.
En este artículo queremos contaros cuál ha sido nuestra experiencia intentando explotar datos abiertos. Esta iniciativa surgió un día en una sesión de brainstorming del equipo de Big Data. Ese día dimos con la web de Open Data del Ayuntamiento de Madrid, la cual contiene colecciones de datos abiertos del ayuntamiento que puedes utilizar descargándolos e incluso explotándolos vía API. Tras analizar las fuentes que ofrecían y el potencial que podían tener se nos ocurrió que si esas fuentes se pudieran correlar podríamos generar contenido útil, valioso e interesante tanto para ciudadanos como para distintas áreas del Ayuntamiento.
A continuación os contamos nuestra experiencia.
Datos
Inicialmente pensamos en dos casos de uso: uno de ellos zonas calientes de accidentes de tráfico y multas, y el segundo análisis del impacto de la calidad del aire en la salud de la ciudadanía. Nos vamos a centrar en el primero de ellos, que es el que los datos nos han permitido crear de manera más óptima. Para ello contábamos con las siguientes fuentes:
- Accidentes de tráfico.
- Accidentes con implicación de bicicletas.
- Multas de tráfico.
- Intervenciones del Samur.
Retos
El primer reto al que nos enfrentamos fue el procesamiento de los datos. El hecho de que los datos en cada fuente no estuvieran normalizados hizo que se disparase el tiempo invertido en hacer de ellos datos útiles para aplicar lógicas y análisis, ya que dichos datos no siguen el mismo formato en los distintos conjuntos de datos. Por ejemplo, la ubicación no se detalla igual en los accidentes de tráfico que en las multas (calles con distintos formatos), o en las intervenciones de Samur que en lugar de especificar la calle se especifica únicamente el distrito.
Tras una labor de “cocinado” de los datos que los habilitara para incluirlos en Splunk, vino el problema de la correlación. Nos faltaban campos en algunas fuentes con las que relacionarlas con el resto de datos; y datos básicos como la fecha completa estaban ausentes en algunas de ellas. Esto hizo que el nivel de detalle que se puede llegar a obtener se viese disminuido, ya que sólo se puede analizar por mes y año, con lo que las conclusiones pueden ser distorsionadas.
Un claro ejemplo de diferencia entre formatos lo encontramos en la ubicación de accidentes y multas. En los datos de accidentes venía la calle, por lo que haciendo una correlación con datos de callejero pudimos obtener coordenadas para geoposicionamiento; sin embargo, en los de multas venían calles incompletas y cruces, lo cual dificultó la posibilidad de posicionar geográficamente.
Otro problema que encontramos fue la falta de datos actuales. Para poder materializar la idea que teníamos en mente lo óptimo hubieran sido datos actualizados de manera diaria, pero nos encontramos con que muchos de los datos que ofrece la web de open data se publican de manera anual a año vencido. Para hacer un “análisis forense” a tiempo pasado y analizar el histórico puede ser útil, pero pierde la versatilidad y el valor que te da tener datos cercanos a tiempo real.
No obstante, seguimos trabajando en ello para ver el potencial que podía tener la idea, y a continuación os contamos lo que conseguimos.
Resultado
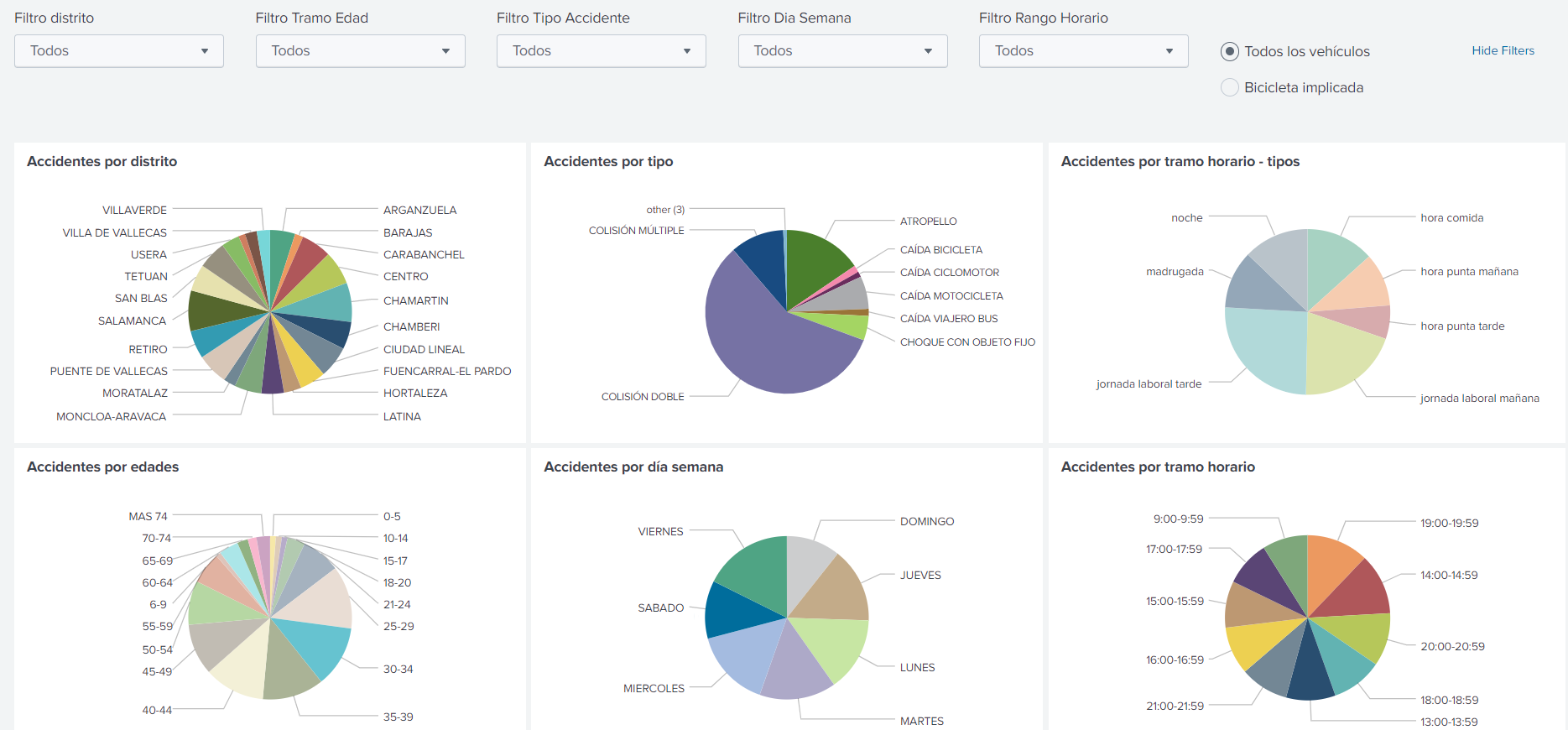
Hemos conseguido desarrollar un dashboard de analytics sobre los datos obtenidos sobre accidentes de tráfico. Tenemos distintas visiones de los accidentes que se producen, pudiendo ver la segregación por distrito, tipo de accidente, edades y horas/días.
Como podemos ver, y sin aplicar ningún tipo de filtro ya podemos empezar a sacar conclusiones:
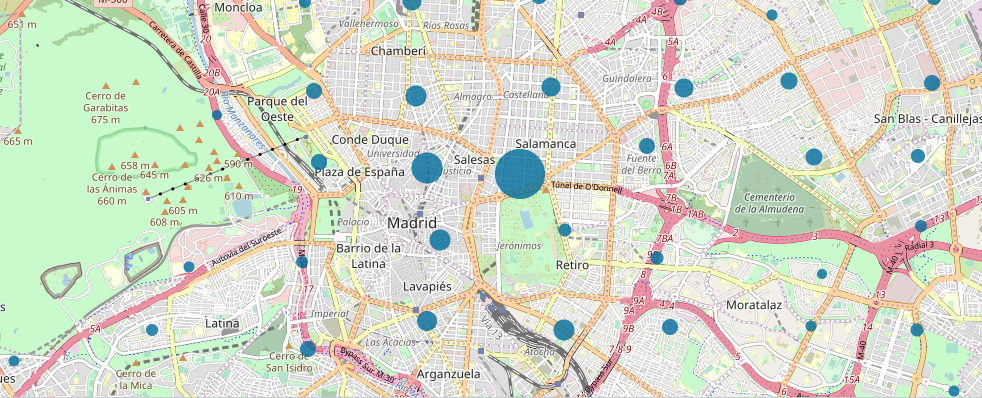
- En cuanto a distritos, los accidentes de tráfico se reparten de manera bastante homogénea, no destacando ningún distrito sobre otro. Tiene un porcentaje ligeramente mayor el distrito de Chamartín pese a que cualquiera pensaríamos que sería el distrito Centro.
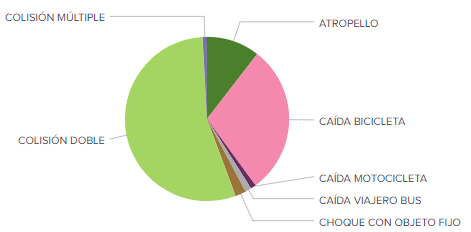
- Los accidentes que más se producen son colisiones dobles, acaparando así un 75% de todos ellos. Llama la atención una tipología de accidente con suficiente representación como para salir en el gráfico que es “Caída viajero bus”.
- Los resultados de tramo horario son totalmente los esperados y deducibles por la afluencia de coches correlando los tramos horarios con las horas de trabajo.
- El abanico de edades que se registran va de 0 a más de 74 años. Es curioso ver como la segregación de accidentes va en aumento en los tramos menores de edad hasta llegar a los 25-29 (un 12,44% de los accidentes), y a partir de ese tramo empieza a disminuir de nuevo.
- El lunes gana por poco margen el día con más accidentes de tráfico, siendo el resto bastante equitativos.
- Respecto a las horas, refleja que hay más accidentes por la tarde que por la mañana. Esto puede dar lugar a pensar que los desplazamientos para trabajar por la mañana pueden estar más escalonados que los de la tarde.
Los filtros superiores nos permiten “jugar” con la información, para obtener conclusiones curiosas como las siguientes:
- Seleccionando accidentes cuyos implicados tienen una edad superior a 74 años vemos como la segregación por tipo de accidente aumenta considerablemente hacia “Atropello”, y que la tipología “Caída viajero bus” se ve incrementada.
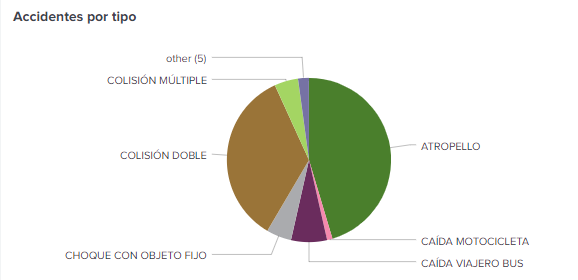
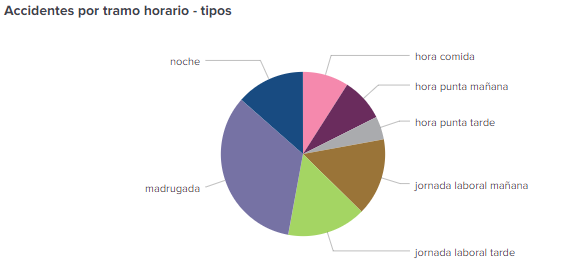
- Si queremos analizar los accidentes de tipo “Choque contra objeto fijo” llama la atención de éstos a qué hora se producen más, como vemos en el siguiente gráfico. Es el horario de madrugada y noche el que se lleva casi el 50% de estos accidentes.
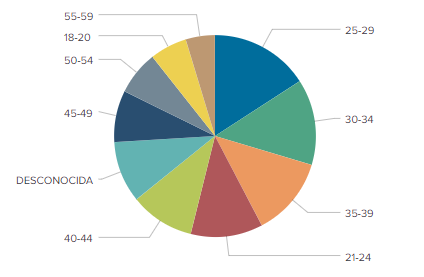
- Al seleccionar accidentes producidos de madrugada y por la noche, las edades que más aparecen son de los 21 a los 39 años. Sin embargo, la división por días de la semana es más homogénea de lo que se esperaría

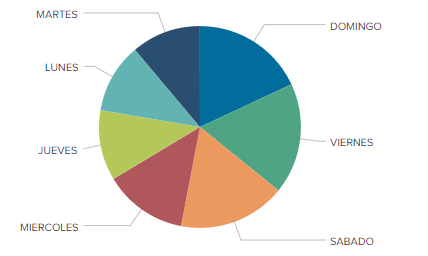
- Sorprende que seleccionando aquellos accidentes con bicicleta implicada, en tipología siga saliendo “Caída viajero bus”.
- Analizando el geoposicionamiento de accidentes se aprecia una ocurrencia mayor por el barrio de Salamanca, siendo el resto repartido homogéneamente.
- Si contamos los accidentes por día/tramo horario, tipo de accidente, gravedad y tramo de edad los accidentes que más se producen son los sábados de 00 a 00:59, la mayoría por colisión doble, sin heridos de gravedad y en tramos de edades bastante dispares.

- Por último, algo de esperar, si vemos un gráfico con la evolución temporal de los accidentes por mes apreciamos que en el mes de Agosto disminuyen drásticamente. Llama la atención el aumento en Octubre sin mucha razón lógica a la que achacarlo.

Qué hubiéramos necesitado para conseguirlo
Para conseguir lo que teníamos en mente hubiéramos necesitado principalmente:
- Campos para correlar las distintas fuentes.
- Datos en real time o near real time.
- Presencia de datos ausentes: por ejemplo, día del mes el cuál no está presente y dificulta aplicar ciertos análisis (por ejemplo, analizar los accidentes en función de medidas de contaminación activas).
- Calidad en los datos, por ejemplo, en los de ubicación.
Conclusiones
Pese a que se ha avanzado mucho en estos temas y ya se ha dado un gran paso como crear un servicio de consumo de datos abierto de los ayuntamientos (presente no sólo en Madrid, sino también en ciudades como Barcelona), aún queda camino por andar.
Hemos extraído bastantes conclusiones, pero si hubiésemos contado con todo lo necesario se podría haber hecho algo con mucho más potencial permitiendo extraer todo el jugo que los datos y la correlación entre estos aportan.
Esperamos que el mundo de los datos siga evolucionando, ¡nosotros estaremos ahí para experimentarlo y vivirlo!
Autora: Nerea Sánchez Fernández, Area Manager Big Data





